텐서플로 튜토리얼인 www.tensorflow.org/tutorials/text/nmt_with_attention 을 참고했다.
사실 다른 튜토리얼인 Transformer 를 사용한 번역기 모델을 사용하고 싶었는데
1) 내일 배울 내용이고 2) 코드를 봐도 도통 모르겠어서
일단 텐서플로 튜토리얼을 차근차근 따라 해 보기로 했다!
1. 데이터셋 변경
튜토리얼은 영어-스페인어 패키지로 되어 있다. 무려 10만 개의 데이터셋이라고...
www.manythings.org/anki/ 에서 eng-kor 데이터셋을 받아주고,
ipynb 노트북에 있는 모든 스페인어(sp, spa, 관련 변수명을 kor로 다 바꿔준다.
!unzip "kor-eng.zip"
!ls # zip 푼 파일들이 보임
path_to_file = 'kor.txt''kor.txt'는 zip을 풀면 나오는 훈련에 쓰일 데이터셋이다.
튜토리얼 안에서 여러 번 쓰이는 변수라, 변수명을 파일 이름으로 맞춰준다.
한국어 처리용 정규식
def preprocess_sentence(w):
w = unicode_to_ascii(w.lower().strip())
# 단어와 단어 뒤에 오는 구두점(.)사이에 공백을 생성합니다.
# 예시: "he is a boy." => "he is a boy ."
# 참고:- https://stackoverflow.com/questions/3645931/python-padding-punctuation-with-white-spaces-keeping-punctuation
w = re.sub(r"([?.!,¿])", r" \1 ", w)
w = re.sub(r'[" "]+', " ", w)
# (a-z, A-Z, ".", "?", "!", ",")을 제외한 모든 것을 공백으로 대체합니다.
w = re.sub(r"[^a-zA-Z가-힣?.!,¿]+", " ", w)
w = w.strip()
# 모델이 예측을 시작하거나 중단할 때를 알게 하기 위해서
# 문장에 start와 end 토큰을 추가합니다.
w = '<start> ' + w + ' <end>'
return w원 튜토리얼은 영어와 스페인어가 둘 다 로마자 기반의 알파벳 언어라, 정규식을 사용할 수 있는 함수가 동일했다.
하지만 한국어는 아니라, 한국어 전용 전처리 함수를 새로 만들어주어야 한다.
def preprocess_sentence_kr(w):
w = w.strip()
# 단어와 단어 뒤에 오는 구두점(.)사이에 공백을 생성합니다.
# 예시: "he is a boy." => "he is a boy ."
# 참고:- https://stackoverflow.com/questions/3645931/python-padding-punctuation-with-white-spaces-keeping-punctuation
w = re.sub(r"([?.!,¿])", r" \1 ", w)
w = re.sub(r'[" "]+', " ", w)
w = re.sub(r'[ |ㄱ-ㅎ|ㅏ-ㅣ]+', " ", w)
w = w.strip()
# 모델이 예측을 시작하거나 중단할 때를 알게 하기 위해서
# 문장에 start와 end 토큰을 추가합니다.
w = '<start> ' + w + ' <end>'
return w
데이터셋 처리

zip 파일을 풀면 나오는 텍스트 파일은 이런 식인데,
import pandas as pd
data = pd.read_csv('kor.txt', delimiter = "\t")
data.columns = ["en", "kor", "cc"]
datapd.read_csv 로도 텍스트 파일을 열 수 있다.
열어서 데이터 프레임 형식으로 바꿔준다.
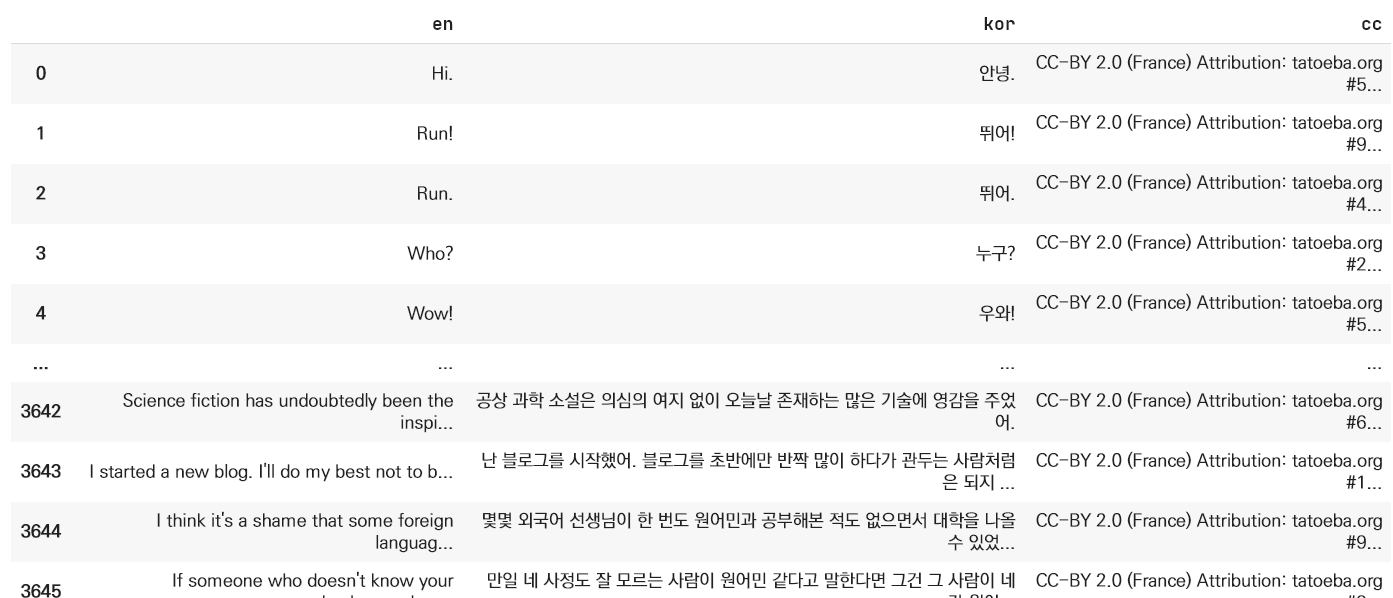
영어, 한국어 맵핑하기
데이터셋을 불러오고, 전처리 해주는 과정을 함수화한다.
뒤에서 번역기에서 입력할 문장마다 쓰이기 때문이다.
def create_dataset(path, num_examples):
data = pd.read_csv('kor.txt', delimiter = "\t")
data.columns = ["en", "kor", "cc"]
en = [preprocess_sentence(l) for l in data['en']]
kr = [preprocess_sentence_kr(l) for l in data['kor']]
# 다음과 같은 형식으로 문장의 쌍을 반환합니다: [영어, 한국어]
return en, kr # 이렇게 하면 한->영 번역이 됨
영어, 한국어 순으로 리턴을 하는데, 이렇게 하면 한국어를 입력하면 영어 번역이 나오는 한영 번역이 된다.
뒤에서 타겟 언어, 입력 언어 이렇게 변수를 받기 때문이다.
targ_lang, inp_lang = create_dataset(path, num_examples)
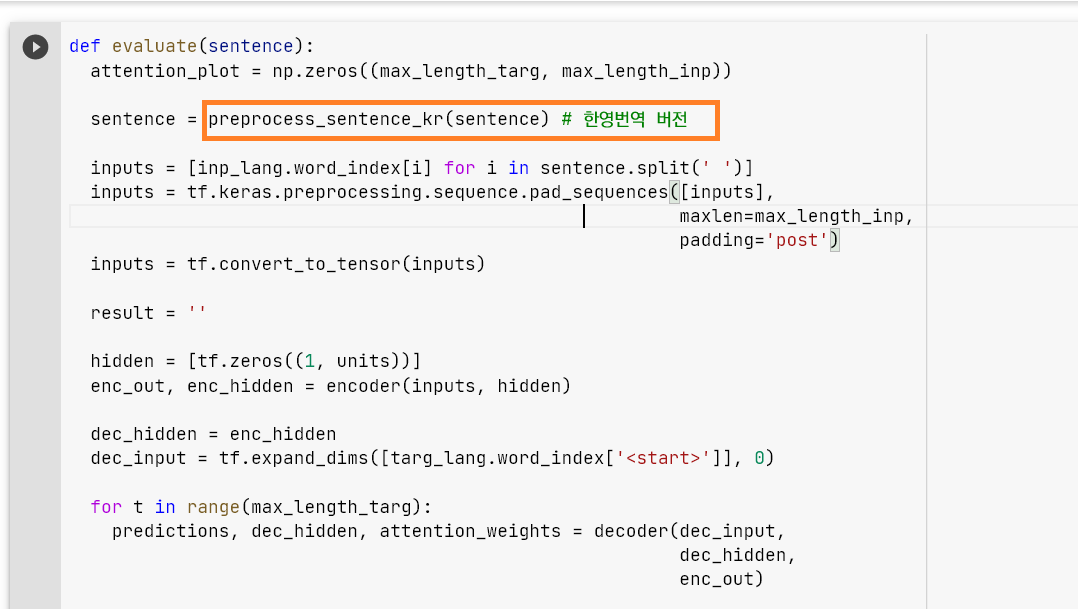
그리고 뒷부분에 있는 이 함수도 한국어 전처리 버전으로 바꾸어 주면 된다.
안 하면 다음과 같이 인풋 언어가 제대로 보이지 않는다.

이렇게.. 인풋 언어가 안 보인다.
만약 영어 문장을 입력하면 한국어를 번역해주는 영한 번역기를 만들고 싶다면,
def create_dataset(path, num_examples):
data = pd.read_csv('kor.txt', delimiter = "\t")
data.columns = ["en", "kor", "cc"]
en = [preprocess_sentence(l) for l in data['en']]
kr = [preprocess_sentence_kr(l) for l in data['kor']]
# 다음과 같은 형식으로 문장의 쌍을 반환합니다: [영어, 한국어]
return kr, en # 이렇게 하면 한->영 번역이 됨
이렇게 kr, en 순으로 고치면 된다.
성능
4시간 만에 튜토리얼 따라 하며 만든 번역기 성능이 어떻겠습니까... 예...
한국어를 넣었더니 영어가 나오는 것으로 만족합니다...
데이터셋에 있는 문장이라면 정확한 번역이 나온다.

하지만 데이터셋에 각각의 토큰은 있지만, 완전 같은 문장은 없다면
모자란 번역이 도출된다.

다음으로는 내가 그간 번역했던 영어 자막-한글 자막 데이터들을 모아, 학습을 시켜보았다.

- 2020년 실제로 번역하여 작업했던 영화 자막을 학습시켰다.
- 5편의 영화로, 총 3877 line의 영어, 한국어 텍스트가 있다.
- 내가 번역 과정에서 활용할 수 있는 좀 더 자연스러운 말투의 기계 번역,
실제 번역자가 작업하며 참고할 수 있는 말투, 단어의 제안을 위해 내가 번역했던 텍스트를 사용하였다.
영화 자막은 2명의 인물이 말할 때
- 오늘 뭐 먹었어?
- 참치회
와 같이 '- '로 구분 기호를 붙인다.
기울임 처리는<i >기울이는 문장</i>으로 하고,
폰트 색깔은 <FONT COLOR= "FFFF00"> 영화 제목 </FONT>으로 처리한다.
외에 영화의 제목, 감독, 제작자 등을 잡아주는 화면 자막이 있는데,
영어-> 한국어를 매끄럽게 번역하기 위해, 이 요소들을 삭제했다.
학습 결과,
위에서 사용했던 영어-한국어 학습용 데이터셋을 사용한 것보다 성능은 더 떨어졌다.. ㅎ
데이터셋에 토큰이 없으면 사실 번역이 안 되는 건 괜찮은 게,
나는 앞으로 번역 툴을 만드면서 (영어) 문장마다
1. 예전 번역 메모리에서 이 문장과 유사한 문장을 번역했거나, 감수 과정에서 어떻게 고쳤는지 찾음
2. 그걸 "추천" 형식으로 뜨게 함
방식을 서구상하고 있기 때문이다.
무튼, 번역가가 (성능은 한참 모자라지만) 번역기도 만들어보고 신난다!
'머신러닝, 딥러닝' 카테고리의 다른 글
| Transformer를 사용한 인공 신경망 한영 번역기 코드 예제 실습 (Colab 버전) (0) | 2021.04.18 |
|---|---|
| Transformer를 사용한 인공 신경망 한영 번역기 코드 예제 실습 (0) | 2021.04.16 |
| spacy [E050] Can't find model 'en_core_web_sm' 에러 해결 (0) | 2021.04.12 |
| 초등학생도 이해하는 역전파 (0) | 2021.04.09 |
| clf = RandomForestClassifier() 같이 변수를 설정해주는 이유 (0) | 2021.03.01 |

