프렌즈 스크립트로 딥러닝 모델을 학습했다는 논문이 있어서,
프렌즈 한영자막을 넷플릭스에서 구해서 학습 데이터로 써볼까 하다가 프렌즈는 살짝 오래된 감이 있어서
모던 패밀리로 해보기로 했다. 이것도 오래되긴 했지만...!
LLN 플러그인을 사용하면 한영자막을 쉽게 엑셀 파일로 추출할 수 있어서, 시즌 1-3 + 법정물(슈츠 5화 정도) + 스탠드업 코미디 5화 분량을 일단 추출했다.
꽤 노가다라 매크로로 할 수 있나 찾아보니, 파이썬에도 매크로 만드는 파일이 있어서
추후 학습 데이터가 더 필요하면 코드를 짜봐야겠다.
그리고 전처리 작업을 계속 했는데, 흡사 알고리즘 푸는 것 같았다.


넷플릭스로 추출한 자막은 영어 문장 스파팅이 이상하거나, 타임이 겹칠 때면 (LNN 플러그인으로 추출한 자막은)
저렇게 자막이 2번씩 나온다.
저걸 어떻게 중복되는 걸 없애면서 번역기 학습 데이터로 쓸 수 있도록 영-한 문장이 pair가 될 수 있을까 생각해봤는데,
1. 반복문을 돌면서 이전 문장과 현재 문장을 비교한다.
2. 현재 문장이 이전 문장에 포함되어 있다면(이전 문장이 더 김) 현재 줄의 영어 부분만 앞줄에 붙인다.
그리고 현재 줄을 삭제한다.

바로 이 경우다.

뒷 문장의 한글은 지우고, 영어만 윗 문장에 붙인다.
3. 이전 문장이 현재 문장에 포함되어 있다면(현재 문장이 더 길다) 앞 문장의 영어 부분만 이번 줄에 붙인다.
그리고 전 줄을 삭제한다.
꽤 간단한데 코드를 검색해도 바로 안 나와서 삽질을 좀 했다.
하지만 해결책은 의외로 간단했다...!
previous = "첫 줄의 문장"
for i in range(1,len(df)):
#print(df.iloc[i,0]) # en
# 이전 문장이 현재 문장과 중복되는 부분이 있으면(뒷 문장이 더 김)
if previous in df.iloc[i,1]:
df.iloc[i,0] = df.iloc[i-1,0] + ' '+ df.iloc[i,0] # 뒷 문장에 내려서 합치고
df = df.drop(df.index[i-1]) # 이전 문장을 지운다
previous = df.iloc[i,1]
# 현재 문장이 이전 문장과 중복되는 부분이 있으면 (이전 문장이 더 김)
if df.iloc[i,1] in previous:
df.iloc[i-1,0] = df.iloc[i-1,0] + ' '+ df.iloc[i,0] # 이전 문장에 올려서 합치고
df = df.drop(df.index[i]) # 현재 문장을 지운다
previous = df.iloc[i-1,1]
else: # 중복이 아니면
previous = df.iloc[i,1] # 현재 문장을 previous 로 만들고 루프 돌리기
중복되는 한글 문장은 어떻게 할까 고민했었는데, 애초에 안 합치고 지우면 된다.
영어 문장을 합쳐야 하는 경우, 저렇게 df.iloc[i-1,0] + ' ' + df.iloc[i,0] 으로 해당하는 줄의 영어 부분만 합칠 수 있었다.

YOLO를 사용한 텍스트 인식 모델 TextFuseNet 의 경우,
원 작성자가 기재한 대로 파일을 돌리면 다른 폴더에 예측된 결과와 폴리곤 좌표(인식된 텍스트의 위치 정보) 만 나온다.
3일에 걸쳐 레파지토리 안의 코드를 뜯어보며 텍스트만 추출한 결과물은 어떻게 뽑을 수 있나 찾아봤다.
텍스트 인식이 나오긴 한다는 거야? 하고 논문까지 꼼꼼히 읽어봤는데
인식된 결과물에 Text와 알파벳 정보가 있는 걸로 보아 인식되는 게 분명했다.
Vscode로 'label' 'prediction' 'text' 'ground trouth' 등 검색해가며 샅샅히 뒤져봤다..ㅋㅋㅋ
다행히 원 작성자가 주석을 꼼꼼히 달아놔서, 결과물은 뭔지, 각 코드가 뭔지 어렵지 않게 파악할 수 있었다.

그래서 결국 텍스트를 뽑아낼 수 있었으나, 애초에 사진을 보고 인식률이 좋지 않음을 알아야 했다...
텍스트 인식을 해봤자 정확하지 않고 한 단어라도 빠지면 단어, 문장이 성립이 안 되기 때문이다.
위 사진의 경우 저렇게 기울어진 단어는 순서대로 예측하지 못했는데, 이건 데이터셋이 수평적인 단어가 있는 사진 세트라 그런 듯 하니 다른 모델로도 한번 돌려봐야겠다.
무튼 훈련을 시키면 좀 나아질까 싶지만, 결과물이 허망하다 ㅜ.ㅜ
github.com/cs-chan/Total-Text-Dataset 에서
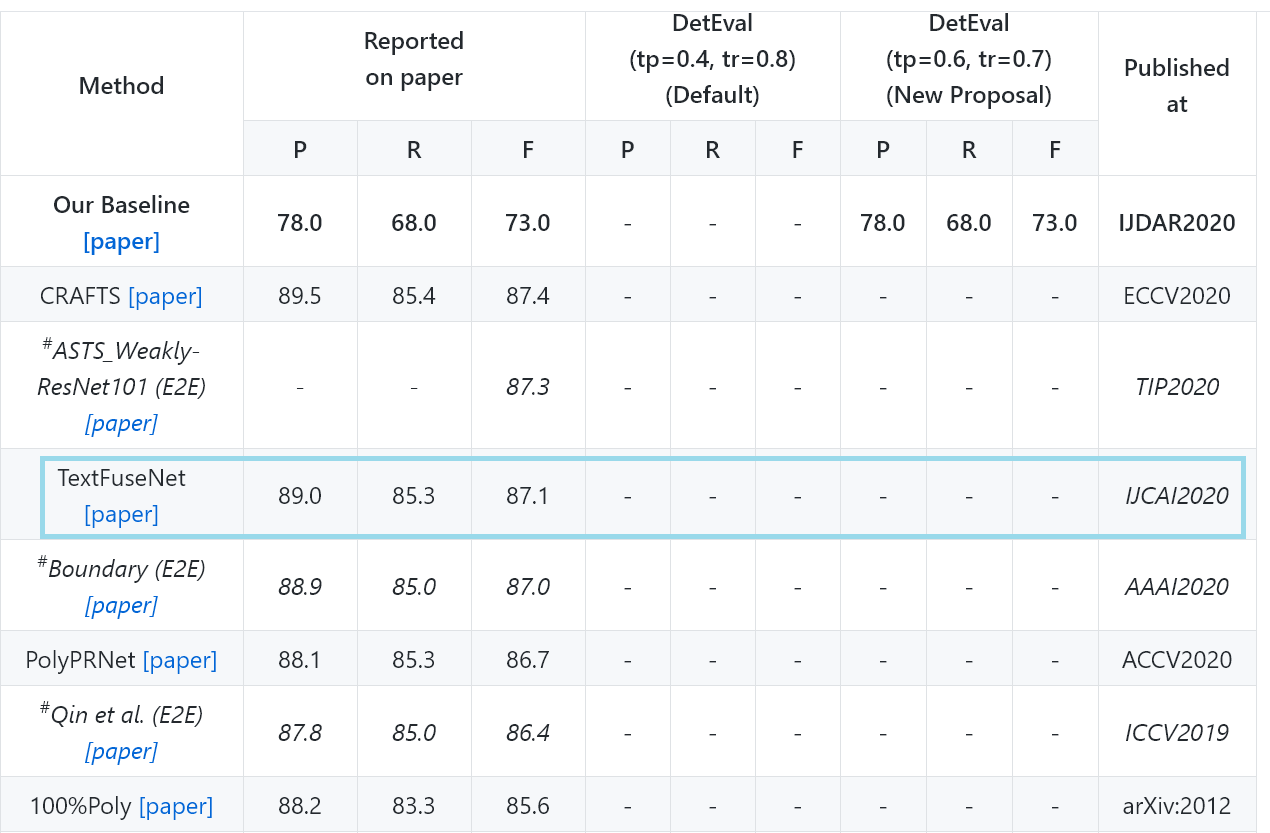
인식률 3위인 모델이라는데, 음.... pre-trained 만 된 상태라서 그런가, 결과물이 아직 그렇게 좋지는 않아서 살짝 실망이다.
애초에 레파지토리 Readme에 텍스트 추출까지 없을 때 알아봤어야 했나...!
'머신러닝, 딥러닝' 카테고리의 다른 글
| 딥러닝 프로젝트 4 : mT5 모델로 번역기 만들기 (2) | 2021.04.28 |
|---|---|
| 딥러닝 프로젝트 3 : Tatoeba opus set, simpletransformers (0) | 2021.04.26 |
| 딥러닝 프로젝트 1: 번역 모델을 위한 삽질 (0) | 2021.04.24 |
| skimage 이미지 일괄 리사이즈 방법 (0) | 2021.04.23 |
| RCNN을 이용한 Object Detection 따라해보기 1 (0) | 2021.04.20 |


