json 파일은 어떻게 여는 건지, 파이참으로 열면
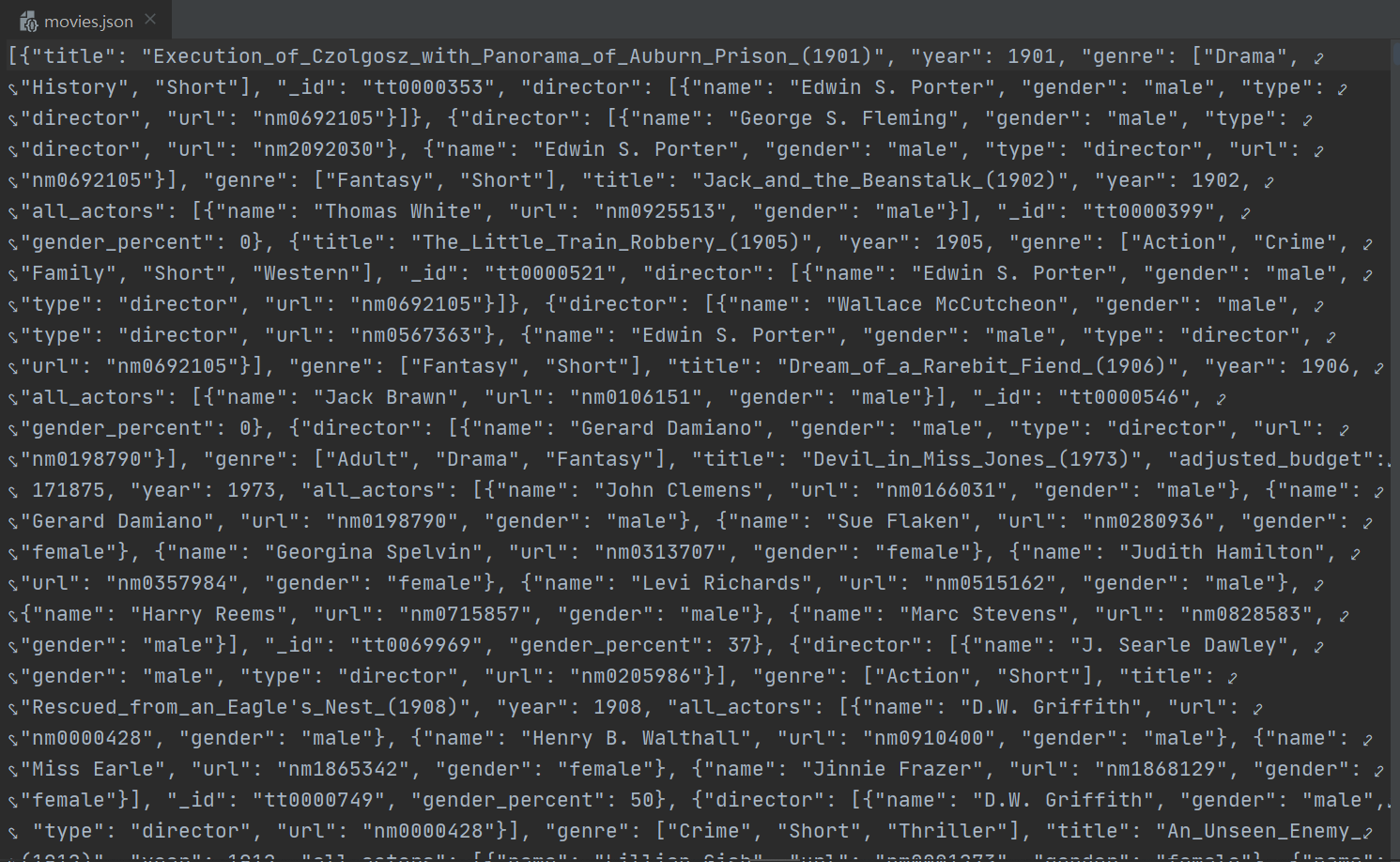
이렇게 뭔 암호같은 딕셔너리만 가득해서 무서웠는데.. ㅋㅋㅋ
사실 별 거 아니었다!
이 포스팅에서는 구글 드라이브에 마운트하는 방법을 다루지만,
그냥 런타임에 올리고 똑같이 해도 된다.
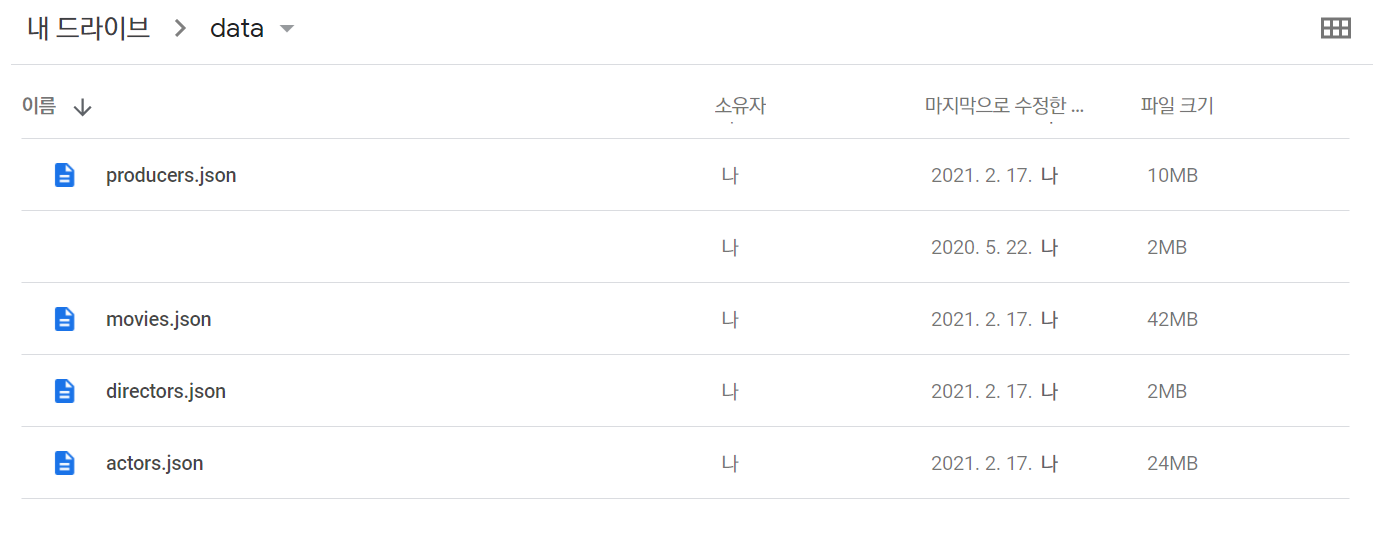
먼저 구글 드라이브 내에 폴더를 새로 파서,
json 파일을 넣어준다.
from google.colab import drive
drive.mount('/content/drive')구글 드라이브에 마운트 해 주고,
# 파일 넣어둔 폴더로 이동
% cd /content/drive/본인경로파일을 넣어둔 구글 드라이브 폴더 경로를 넣어준다. (해당 폴더로 경로 이동)
(생략 가능 : 파일 미리보기)
# json 파일 프린트
from glob import glob
for filename in glob('*.json'):
print(filename)이렇게 하면 해당 폴더의 json 파일을 모두 불러올 수 있는데,
# 각 파일의 shape, head 출력
from IPython.display import display
def preview():
for filename in glob('*.json'):
df = pd.read_json(filename)
print(filename, df.shape)
display(df.head())
print('\n')
preview()다음의 코드로 각 파일의 shape와 head를 출력할 수 있다.
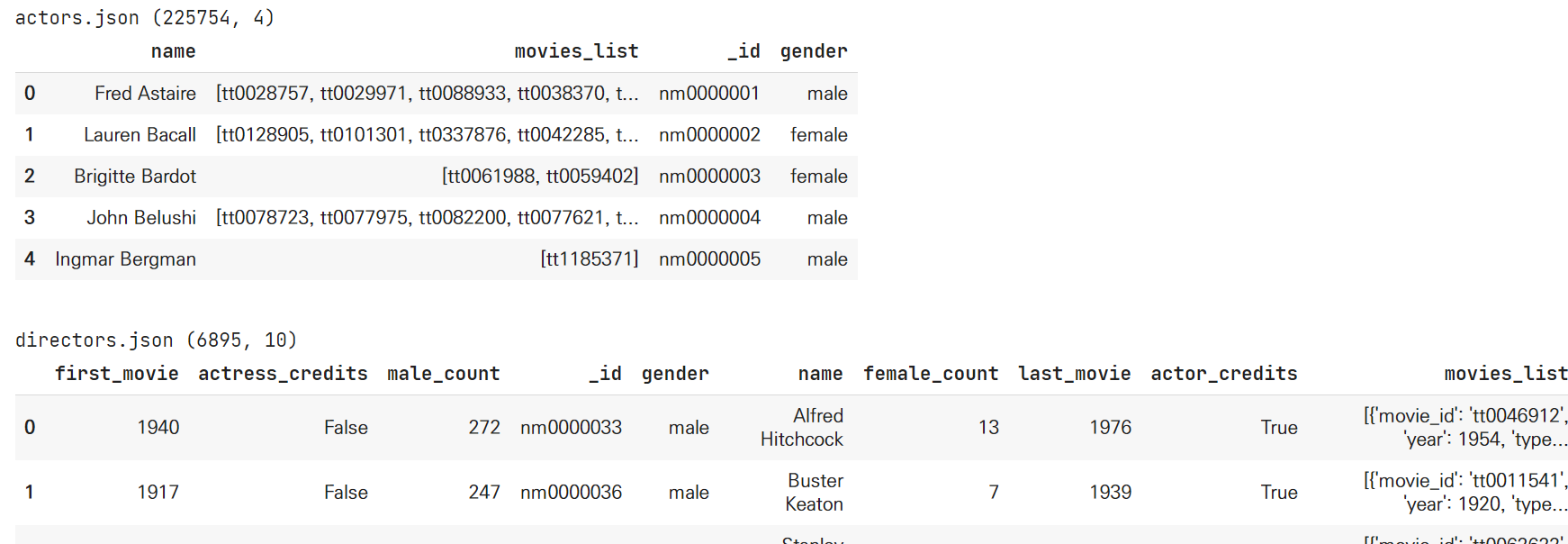
위의 과정은 사실 생략 가능하고,
판다스의 pd.read_json으로 파일을 읽어와 변수에 저장하는 것만 해도 된다.
actors = pd.read_json('actors.json')
directors = pd.read_json('directors.json')
movies = pd.read_json('movies.json')
producers = pd.read_json('producers.json')만약 데이터가

이런 식으로 리스트 안에 딕셔너리가 있는 식이라면,
pd.read_json(df, orient='records')를 하면 데이터가 잘 분리된다.
하지만 한 column만 그런 경우엔 작동하지 않는데.. ^^
이거 때문에 시간 엄청 날렸다.
해결하면 방법 추가하겠음...
'개발' 카테고리의 다른 글
| 코랩(Colab) 노트북 전체 페이지 html 파일로 저장하기 (0) | 2021.02.25 |
|---|---|
| IMDb 인물 정보로 성별 구별하기 (0) | 2021.02.23 |
| 코랩 Colab 폰트 맞춤설정하는 방법 (0) | 2021.02.11 |
| 리디셀렉트 - 데이터 분석가의 숫자유감 (1) | 2021.01.24 |
| 이진 탐색 트리의 개념 (0) | 2020.12.12 |


