CCTV로 이상행동 탐지를 해보고 싶어, 레파지토리를 찾아보다가 마땅히 잘 돌아가는 코드가 없어서
직접 논문을 읽어보고 코드를 짜야겠다 싶었다.
참조한 논문은 다음과 같다.
https://arxiv.org/abs/1412.0767
Learning Spatiotemporal Features with 3D Convolutional Networks
We propose a simple, yet effective approach for spatiotemporal feature learning using deep 3-dimensional convolutional networks (3D ConvNets) trained on a large scale supervised video dataset. Our findings are three-fold: 1) 3D ConvNets are more suitable f
arxiv.org



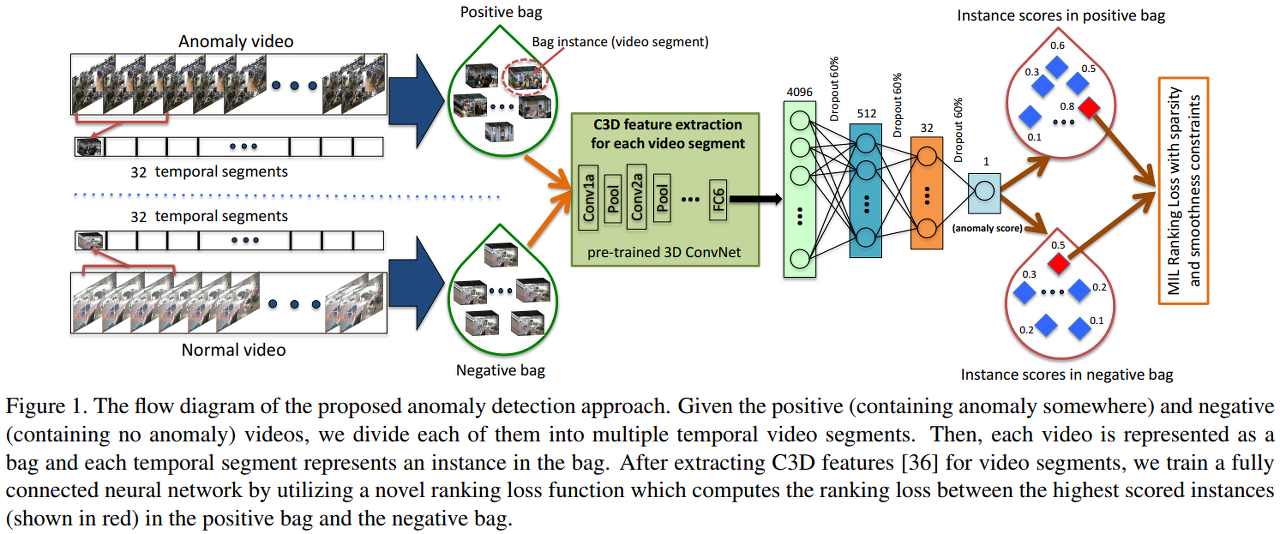
페이스북이 만든 C3D 모델은 개별 영상을 32개의 조각으로 나누어 어떤 이상행동(폭행/싸움/데이트폭력/침입/납치 등)과 가장 가까운지 점수를 매긴 후, 분류하는 방식이다.
먼저 C3D는, 3D Convolution Networks를 대량의 영상 데이터에 지도학습 방식으로 훈련한 모델이다.
- 시공간적 성격을 띄는 데이터의 학습에 잘 맞으며
- 3x3x3 커널 구조로 가장 좋은 성능을 보였다.
- 간단한 선형분류 방식으로도 2015년 당시의 모델과 성능을 견줄만 했다. (정확도 최대 52.8%)
비디오 데이터셋을 딥러닝으로 학습시킨다면 이상 행동 탐지, 행동 인식 등을 할 수 있다. 이 논문은 큰 규모의 비디오 데이터셋을 작은 데이터규모와 같은 모델로 학습할 수 있는 방법을 다루는데,
영상을 다루는 딥러닝 모델은 수천 개의 비디오가 있어도 잘 처리하고, 실시간 데이터(영상)도 빠르게 처리할 수 있어야 한다. 그리고 간단한 모델(선형분류)에서도 잘 작동해야 좋은 분류기라고 할 수 있다.(라고 자기들이 선형분류를 쓴 페이스북 팀은 말했다.ㅎㅎ..)
C3D 모델의 특징은 행동, 사물, 풍경 등 레이블이 달라져도 매번 fine-tuning 할 필요가 없다는데 이건 글쎄...?? 🤔해야 하지 않나?
기존 연구(2015년 기준) 에서 2D Convolution Layer로 비디오 데이터를 분석하곤 했는데, 이러면 시공간적인 특징을 잃기 때문에 성능이 좋지 않게 나온다. 반면 3D Convolution Layer 레이어를 사용하면 사람의 행동을 인식하고, 의학적인 영상에서의 인식, 큰 데이터셋에서도 성능이 좋게 나온 연구들이 있었다. 하지만 영상을 처리할 때 비디오 프레임을 자르는 경우가 있는데, 반면 C3D 모델은 이미지 프레임을 자르지 않는다. 전처리를 하지 않는 편이다.(라고 하지만 이미지 크기를 제한하긴 한다. 뒤에 나올 예정)

(왼쪽부터 1,2) 이미지 여러 장이나 영상을 2D ConvNet에 거치면 시간적인 특징을 잃는다. 매 컨볼루션 레이어마다 그렇다.
(맨 우측) 영상은 3D ConvNet으로 처리해야 시간적인 특징을 잃지 않는다. 풀링 레이어도 마찬가지다.(3D Pooling Layer를 사용해야 한다.)
모델 구조
kernel = 3x3x3 구조가 가장 성능이 좋았다.
input size(영상 사이즈) 127x171로 리사이즈했지만, 빠른 처리를 위해 112x112로 자르기도 했다. (자르면 프레임이 잘려서, 안 보이는 행동도 있어 안 좋을 것 같은데..?)
프레임 - 16 프레임으로 했다.
채널 - 3이다. (RGB)
import tensorflow as tf
from tensorflow import keras
from keras.models import Sequential
from keras.layers import Dense, Dropout, Conv3D, MaxPooling3D, Flatten, Dropout
model = Sequential()
input_shape = (16, 128, 171, 3) # 프레임 개수, 영상 높이, 영상 너비, 채널 수영상 크기는 조절 가능하지만, 높이 128에서 258으로 2배를 늘리면 훈련 시간이 4.39배 증가한다. 파라미터는 약 2배 증가한다.
# 1st layer # filter, kernal-높이,깊이,너비의 크기 - 3D 요소를 형성. 3,3,3이 가장 성능이 좋더라...
# padding = same으로 하면 패딩이 균등하게 이루어진다.
model.add(Conv3D(64, kernel_size=(3, 3, 3), activation='relu',padding='same', name='conv1', input_shape=input_shape))
# stride = 1로 input output size 차이가 없게 함
# pooling은 첫번째 레이어만 1x2x2 - 시간적 신호를 너무 일찍 merge 시키지 않기 위해서
model.add(MaxPooling3D(pool_size=(1,2,2), strides=(1,1,1), padding='valid', name='pool1'))
첫 번째 레이어만 풀링을 1x2x2로 하는데, 시간적 신호를 너무 일찍 merge시키지 않기 위해서이다.
strides는 (1,1,1), 패딩을 해주고, 커널 사이즈는 (3,3,3)으로 하는 편이 가장 성능이 좋았다.
padding = valid로 하면 패딩이 없고, same으로 하면 패딩을 균등하게 한다.
strides를 2,2,2로 준 레파지토리도 있었다. https://github.com/axon-research/c3d-keras/blob/master/c3d_model.py
axon-research/c3d-keras
C3D for Keras + TensorFlow. Contribute to axon-research/c3d-keras development by creating an account on GitHub.
github.com
일단 나는 논문 구현이 목적이라, 논문에 나온 대로 했는데... 램이 터진다. ^^....
무튼 계속 가보자.
# 2nd layer
model.add(Conv3D(128,kernel_size=(3, 3, 3), activation='relu',padding='same', name='conv2', input_shape=input_shape))
model.add(MaxPooling3D(pool_size=(2,2,2), strides=(1,1,1), padding='valid', name='pool2'))
# 3rd layer
model.add(Conv3D(256, kernel_size=(3, 3, 3), activation='relu',padding='same', name='conv3', input_shape=input_shape))
model.add(MaxPooling3D(pool_size=(2,2,2), strides=(1,1,1), padding='valid', name='pool3'))
# 4th layer
model.add(Conv3D(256, kernel_size=(3, 3, 3), activation='relu',padding='same', name='conv4', input_shape=input_shape))
model.add(MaxPooling3D(pool_size=(2,2,2), strides=(1,1,1), padding='valid', name='pool4'))
# 5th layer
model.add(Conv3D(256, kernel_size=(3, 3, 3), activation='relu',padding='same', name='conv5', input_shape=input_shape))
model.add(MaxPooling3D(pool_size=(2,2,2), strides=(1,1,1), padding='valid', name='pool5'))
model.add(Flatten())2-5번째 레이어도 비슷하게 해준다. 단 필터의 수는 64->128->256->256->256으로 바뀐다.
특징은 5개의 레이어를 사용하고, 컨볼루션 레이어와 풀링 레이어를 3D를 사용한다는 것이다.
# 2 fully connected layers - 2048 outputs
model.add(Dense(2048, activation='relu', name='fc1'))
model.add(Dropout(.5))
model.add(Dense(2048, activation='relu', name='fc2'))
model.add(Dropout(.5))
# softmax loss layer
model.add(Dense(20, activation='softmax'))
model.summary()그리고 2048 output을 갖는 fully connected layer를 2개 만들어준다.
Dense를 쓰면 구현할 수 있다. 마지막에는 softmax를 써서, 어떤 행동인지 분류한다.
논문엔 Dropout 얘기는 없었는데, 코랩 램에 터져서 추가해봤다. 그래도 터진다... 그래서 stride를 2로 올리는 걸까.


논문이 친절하게 레이어 구조를 설명해줘서 레벨1을 상대하는 느낌으로 할 수 있었다...!
'머신러닝, 딥러닝' 카테고리의 다른 글
| 스튜디오 4bpm 신메뉴 추천기 만들기 (0) | 2021.06.14 |
|---|---|
| 고양이 사료 추천 시스템 만들기 : 여러 아이템 기반 추천(Item-item collaborative filtering) (1) | 2021.06.07 |
| 딥러닝 프로젝트 4 : mT5 모델로 번역기 만들기 (2) | 2021.04.28 |
| 딥러닝 프로젝트 3 : Tatoeba opus set, simpletransformers (0) | 2021.04.26 |
| 딥러닝 프로젝트 2: 넷X릭스 자막 전처리 (0) | 2021.04.25 |



