
어제 스튜디오 포비피엠 studio 4bpm에 가서 신메뉴를 고민하며 시켜보다가
한 번의 실패를 맛본 후 (으엑 이게 무슨 맛이야... ㅜㅜㅜㅜ)
내가 좋아하는 베이스, 리큐르를 기반으로 메뉴를 추천받을 수 있는 추천기를 만들어보자 싶었다.

두번째로 시킨 메뉴에는 럼이 들어갔는데, 생각보다 내가 럼을 안 좋아했다... ㅋㅋㅋㅋㅋ
그래서 다시 시킨 메뉴가 (진)패션리더™인데, 패션후르츠 기반 리큐르(?), 스파클링 와인이 2개가 들어간다. 그래서 도수가 좀 높은 편이라고 하셨음. 생각보다 독해서 좀 덜 쎄게 해달라고 하니 토닉워터를 타주셨다. 하지만 그러니 이상한 뒷맛이 남았는데...!!!!

치즈말이 곶감은 입에서 사르르 녹았다. 존맛~~
무튼 이제 메뉴를 기반으로 메뉴 분석, 추천을 시작해보겠다.
먼저 메뉴 사진을 찍는다. OCR 인식 시킬 거다.


클로바 OCR을 이용할까 하다가 api 형식이라,
convertio 사이트를 이용했다. 나름 인식률 괜찮다. (무료 사이트라는 것을 감안). 10장까지 인식이 가능하다.

그러면 이렇게 인식되는데, 노가다로 정제화해준다.
import pandas as pd
df = pd.read_csv('4bpm.csv')
df
요렇게~~~
(저는 경쟁업체 관계자가 아니며 오로지 스튜디오포비피엠의 메뉴를 좀더 잘 추천받아 좋은 술생활을 누리고자 이 데이터를 수집 가공하였읍니다)
분석에는 세 가지 항목을 사용할 텐데, 나는 '시그니처 메뉴' '클래식 메뉴' 등의 세부정보, 술 이름, 특징을 사용하기로 했다.
진토닉과 얼그레이 진토닉이 유사하고, 홍차와 보드카가 들어간 칵테일과 홍차와 보드카, 진이 들어간 칵테일이 유사하도록 추천 모델을 만들고 싶었기 때문이다.
df2 = df.loc[:, ['세부','메뉴','특징']]
df2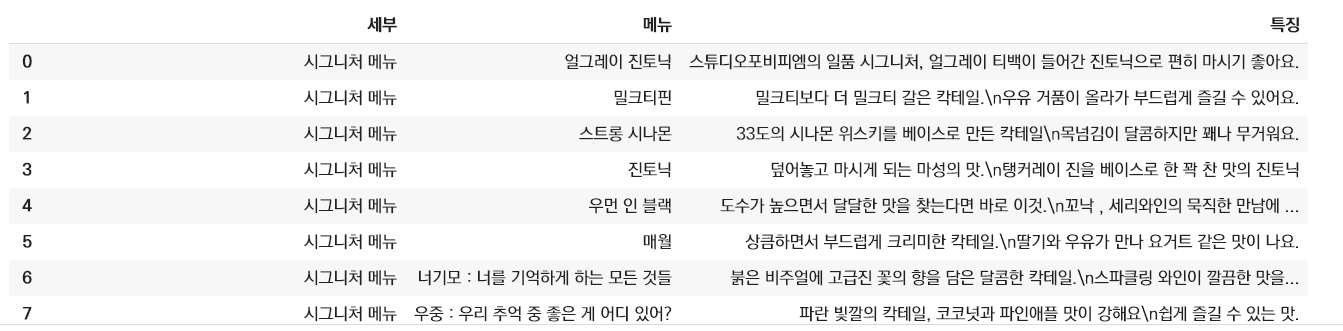
다음으론 이 특징들을 한 칼럼으로 합쳐준다. 분석하기 쉽게 하기 위해서다.
# 한 column에 스트링 형태로 합치기
df2['soup'] = df2['세부'].astype(str) +' ' + df2['메뉴'].astype(str) + ' ' + df2['특징'].astype(str)
df2['soup']
#Import TfIdfVectorizer from scikit-learn
from sklearn.feature_extraction.text import TfidfVectorizer
#TF-IDF Vectorizer 객체를 정의
tfidf = TfidfVectorizer()
#데이터를 적합하고 변환하여 필요한 TF-IDF 행렬을 구성
tfidf_matrix = tfidf.fit_transform(df2['soup'])
#Output the shape of tfidf_matrix
tfidf_matrix.shape # (53, 454)다음은 tf-idf 벡터라이저로 로 저 칼럼 안의 단어들을 숫자로 벡터화해준다.
메뉴 개수 x 454 개의 단어 모음을 가진 행렬이 되었다.
# DataFrame의 인덱스를 재설정하고 역방향 매핑을 구성
df2 = df2.reset_index()
indices = pd.Series(df2.index, index=df2['메뉴'])
indices또 메뉴를 인덱스와 연결시켜준다.

다음엔 linear_kernel로 코사인 유사도를 구한다.(이 방식이 더 빠르다.)
# Import linear_kernel
from sklearn.metrics.pairwise import linear_kernel
# Compute the cosine similarity matrix
cosine_sim = linear_kernel(tfidf_matrix, tfidf_matrix)array([[1. , 0.04324695, 0.0375478 , ..., 0. , 0. , 0. ],
[0.04324695, 1. , 0.03911856, ..., 0.02510153, 0.02584759, 0.044061 ],
[0.0375478 , 0.03911856, 1. , ..., 0.02179361, 0.02244135, 0.03825457],
...,
[0. , 0.02510153, 0.02179361, ..., 1. , 0.29614491, 0.36062922],
[0. , 0.02584759, 0.02244135, ..., 0.29614491, 1. , 0.3713477 ],
[0. , 0.044061 , 0.03825457, ..., 0.36062922, 0.3713477 , 1. ]])다음과 같은 유사도가 나온다.
이제는 위에서 구한 유사도를 바탕으로 가장 유사한 메뉴 3개를 추천해준다. (개수는 마음대로 바꿀 수 있다.)
def get_recommendations(get_title, cosine_sim=cosine_sim):
# Get the index of the movie that matches the title
idx = indices[get_title]
# Get the pairwsie similarity scores of all movies with that movie
sim_scores = list(enumerate(cosine_sim[idx]))
# Sort the movies based on the similarity scores
sim_scores = sorted(sim_scores, key=lambda x: x[1], reverse=True)
# Get the scores of the 3 most similar movies
sim_scores = sim_scores[1:4] # 10개도 가능
# Get the movie indices
movie_indices = [i[0] for i in sim_scores]
# Return the top 3 most similar movies
return df2['메뉴'].iloc[movie_indices]
이렇게 추천된 메뉴들은 다음과 같다. () 안의 메뉴를 입력하면 이와 유사한 메뉴를 추천해준다.

이걸 챗봇으로 만들어도 재밌겠다고 생각중...!
그리고 럼 안 좋아하시면 술잘알 시키지 마십시오...^^
'머신러닝, 딥러닝' 카테고리의 다른 글
| CCTV 이상행동 탐지 프로젝트 - 이상행동 분류하기 (0) | 2021.08.31 |
|---|---|
| Fast api로 머신러닝 기반 웹사이트 만들고 배포하기 (1) | 2021.06.15 |
| 고양이 사료 추천 시스템 만들기 : 여러 아이템 기반 추천(Item-item collaborative filtering) (1) | 2021.06.07 |
| CCTV 영상인식 모델 만들기 1 - C3D 논문 공부+구현 (3) | 2021.05.18 |
| 딥러닝 프로젝트 4 : mT5 모델로 번역기 만들기 (2) | 2021.04.28 |


